6. The Tidyverse
6.1 Overview
The tidyverse is a collection of R packages for data importing, reshaping wrangling, and visualization. All packages share a common design philosophy, that of tidy data, namely that in tidy datasets
- Each variable must have its own column.
- Each observation must have its own row.
- Each value must have its own cell.
These packages are intended to make statisticians and data scientists more productive by guiding them through workflows that facilitate communication, and result in reproducible work products. A very nice introduction and motivation can be found in this RStudio post What is the tidyverse? and Hadley Wickham’s keynote address at the 2017 RStudio Conference.
You can easily load the core of tidyverse packages using library(tidyverse) that loads the following tidyverse packages:
readr(reading data)ggplot2(data visualisation)tibble(handling dataframes)tidyr(reshaping dataframes)dplyr(data manipulation, or wrangling)purrr(functional programming)stringr(working with strings/characters)forcats(working with factors, or categorical variables that have a fixed and known set of possible values)
Together these packages form the basis of the tidyverse data science workflow:
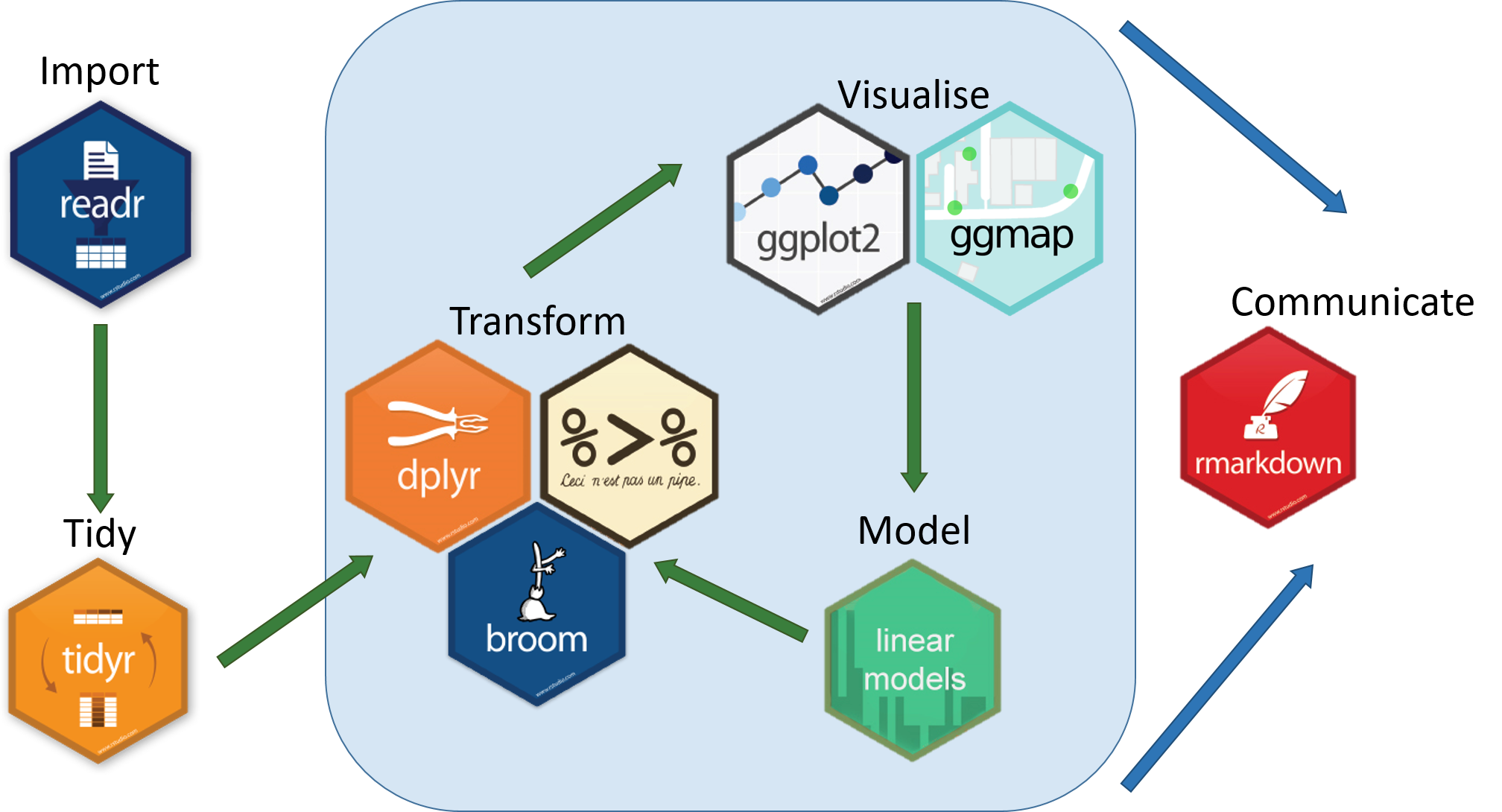
The tidyverse includes many other packages like stringr and lubridate which must be loaded explicitly.
6.2 RStudio’s introductory primers on tidyverse and dplyr
You can work through a few of RStudio’s introductory primers where you type code and see the results.You’ll learn some of the basics of R, as well as some powerful methods for manipulating data with the dplyr package.
- The Basics
- Working with Data
6.3 tidymodels
tidymodels is a meta-package for modelling and statistical analysis that share the underlying design philosophy, grammar, and data structures of the tidyverse.
broomtakes the messy output of built-in functions in R, such as lm, nls, or t.test, and turns them into tidy data frames.inferis a modern approach to statistical inference.recipesis a general data preprocessor with a modern interface.rsamplehas infrastructure for resampling data so that models can be assessed and empirically validated.yardstickcontains tools for evaluating models (e.g. accuracy, RMSE, etc.)tidypredicttranslates some model prediction equations to SQL for high-performance computing.tidyposteriorcan be used to compare models using resampling and Bayesian analysis.tidytextcontains tidy tools for quantitative text analysis, including basic text summarization, sentiment analysis, and text modeling.dialscontains tools to create and manage values of tuning parameters and is designed to integrate well with the parsnip package.
6.4 More resources
This page last updated on: 2020-07-15